v1.77.7-stable - 2.9x Lower Median Latency





Deploy this version
- Docker
- Pip
docker run \
-e STORE_MODEL_IN_DB=True \
-p 4000:4000 \
ghcr.io/berriai/litellm:v1.77.7.rc.1
pip install litellm==1.77.7.rc.1
Key Highlights
- Dynamic Rate Limiter v3 - Automatically maximizes throughput when capacity is available (< 80% saturation) by allowing lower-priority requests to use unused capacity, then switches to fair priority-based allocation under high load (≥ 80%) to prevent blocking
- Major Performance Improvements - 2.9x lower median latency at 1,000 concurrent users.
- Claude Sonnet 4.5 - Support for Anthropic's new Claude Sonnet 4.5 model family with 200K+ context and tiered pricing
- MCP Gateway Enhancements - Fine-grained tool control, server permissions, and forwardable headers
- AMD Lemonade & Nvidia NIM - New provider support for AMD Lemonade and Nvidia NIM Rerank
- GitLab Prompt Management - GitLab-based prompt management integration
Performance - 2.9x Lower Median Latency

This update removes LiteLLM router inefficiencies, reducing complexity from O(M×N) to O(1). Previously, it built a new array and ran repeated checks like data["model"] in llm_router.get_model_ids(). Now, a direct ID-to-deployment map eliminates redundant allocations and scans.
As a result, performance improved across all latency percentiles:
- Median latency: 320 ms → 110 ms (−65.6%)
- p95 latency: 850 ms → 440 ms (−48.2%)
- p99 latency: 1,400 ms → 810 ms (−42.1%)
- Average latency: 864 ms → 310 ms (−64%)
Test Setup
Locust
- Concurrent users: 1,000
- Ramp-up: 500
System Specs
- CPU: 4 vCPUs
- Memory: 8 GB RAM
- LiteLLM Workers: 4
- Instances: 4
Configuration (config.yaml)
View the complete configuration: gist.github.com/AlexsanderHamir/config.yaml
Load Script (no_cache_hits.py)
View the complete load testing script: gist.github.com/AlexsanderHamir/no_cache_hits.py
MCP OAuth 2.0 Support

This release adds support for OAuth 2.0 Client Credentials for MCP servers. This is great for Internal Dev Tools use-cases, as it enables your users to call MCP servers, with their own credentials. E.g. Allowing your developers to call the Github MCP, with their own credentials.
Set it up today on Claude Code
Scheduled Key Rotations
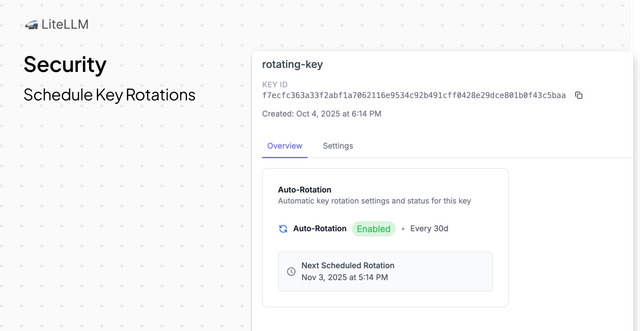
This release brings support for scheduling virtual key rotations on LiteLLM AI Gateway.
From this release you can enforce Virtual Keys to rotate on a schedule of your choice e.g every 15 days/30 days/60 days etc.
This is great for Proxy Admins who need to enforce security policies for production workloads.
New Models / Updated Models
New Model Support
| Provider | Model | Context Window | Input ($/1M tokens) | Output ($/1M tokens) | Features |
|---|---|---|---|---|---|
| Anthropic | claude-sonnet-4-5 | 200K | $3.00 | $15.00 | Chat, reasoning, vision, function calling, prompt caching |
| Anthropic | claude-sonnet-4-5-20250929 | 200K | $3.00 | $15.00 | Chat, reasoning, vision, function calling, prompt caching |
| Bedrock | eu.anthropic.claude-sonnet-4-5-20250929-v1:0 | 200K | $3.00 | $15.00 | Chat, reasoning, vision, function calling, prompt caching |
| Azure AI | azure_ai/grok-4 | 131K | $5.50 | $27.50 | Chat, reasoning, function calling, web search |
| Azure AI | azure_ai/grok-4-fast-reasoning | 131K | $0.43 | $1.73 | Chat, reasoning, function calling, web search |
| Azure AI | azure_ai/grok-4-fast-non-reasoning | 131K | $0.43 | $1.73 | Chat, function calling, web search |
| Azure AI | azure_ai/grok-code-fast-1 | 131K | $3.50 | $17.50 | Chat, function calling, web search |
| Groq | groq/moonshotai/kimi-k2-instruct-0905 | Context varies | Pricing varies | Pricing varies | Chat, function calling |
| Ollama | Ollama Cloud models | Varies | Free | Free | Self-hosted models via Ollama Cloud |
Features
- Anthropic
- Add new claude-sonnet-4-5 model family with tiered pricing above 200K tokens - PR #15041
- Add anthropic/claude-sonnet-4-5 to model price json with prompt caching support - PR #15049
- Add 200K prices for Sonnet 4.5 - PR #15140
- Add cost tracking for /v1/messages in streaming response - PR #15102
- Add /v1/messages/count_tokens to Anthropic routes for non-admin user access - PR #15034
- Gemini
- Ignore type param for gemini tools - PR #15022
- Vertex AI
- Azure
- Ollama
- Add ollama cloud models - PR #15008
- Groq
- Add groq/moonshotai/kimi-k2-instruct-0905 - PR #15079
- OpenAI
- Add support for GPT 5 codex models - PR #14841
- DeepInfra
- Update DeepInfra model data refresh with latest pricing - PR #14939
- Bedrock
- Nvidia NIM
- Add Nvidia NIM Rerank Support - PR #15152
Bug Fixes
New Provider Support
- AMD Lemonade
- Add AMD Lemonade provider support - PR #14840
LLM API Endpoints
Features
-
- Return Cost for Responses API Streaming requests - PR #15053
-
- Add full support for native Gemini API translation - PR #15029
-
Passthrough Gemini Routes
-
Passthrough Vertex AI Routes
-
General
Management Endpoints / UI
Features
-
Virtual Keys
-
Models + Endpoints
-
Admin Settings
-
MCP
Bug Fixes
-
Virtual Keys
-
Models + Endpoints
- Make UI theme settings publicly accessible for custom branding - PR #15074
-
Teams
- fix failed copy to clipboard for http ui - PR #15195
-
Logs
-
Test key
- update selected model on key change - PR #15197
-
Dashboard
- Fix LiteLLM model name fallback in dashboard overview - PR #14998
Logging / Guardrail / Prompt Management Integrations
Features
- OpenTelemetry
- Use generation_name for span naming in logging method - PR #14799
- Langfuse
- Prometheus
- support custom metadata labels on key/team - PR #15094
Guardrails
Prompt Management
Spend Tracking, Budgets and Rate Limiting
- Cost Tracking
- Proxy: end user cost tracking in the responses API - PR #15124
- Parallel Request Limiter v3
- Teams
- Add model specific tpm/rpm limits to teams on LiteLLM - PR #15044
MCP Gateway
- Server Configuration
- Bug Fixes
Performance / Loadbalancing / Reliability improvements
- Router Optimizations
- +62.5% P99 Latency Improvement - Remove router inefficiencies (from O(M*N) to O(1)) - PR #15046
- Remove hasattr checks in Router - PR #15082
- Remove Double Lookups - PR #15084
- Optimize _filter_cooldown_deployments from O(n×m + k×n) to O(n) - PR #15091
- Optimize unhealthy deployment filtering in retry path (O(n*m) → O(n+m)) - PR #15110
- Cache Optimizations
- Worker Management
- Add proxy CLI option to recycle workers after N requests - PR #15007
- Metrics & Monitoring
- LiteLLM Overhead metric tracking - Add support for tracking litellm overhead on cache hits - PR #15045
Documentation Updates
- Provider Documentation
- General Documentation
Security Fixes
- JWT Token Security - Don't log JWT SSO token on .info() log - PR #15145
New Contributors
- @herve-ves made their first contribution in PR #14998
- @wenxi-onyx made their first contribution in PR #15008
- @jpetrucciani made their first contribution in PR #15005
- @abhijitjavelin made their first contribution in PR #14983
- @ZeroClover made their first contribution in PR #15039
- @cedarm made their first contribution in PR #15043
- @Isydmr made their first contribution in PR #15025
- @serializer made their first contribution in PR #15013
- @eddierichter-amd made their first contribution in PR #14840
- @malags made their first contribution in PR #15000
- @henryhwang made their first contribution in PR #15029
- @plafleur made their first contribution in PR #15111
- @tyler-liner made their first contribution in PR #14799
- @Amir-R25 made their first contribution in PR #15144
- @georg-wolflein made their first contribution in PR #15124
- @niharm made their first contribution in PR #15140
- @anthony-liner made their first contribution in PR #15015
- @rishiganesh2002 made their first contribution in PR #15153
- @danielaskdd made their first contribution in PR #15160
- @JVenberg made their first contribution in PR #15146
- @speglich made their first contribution in PR #15072
- @daily-kim made their first contribution in PR #14764